
北理工团队成功研发首个视觉提示遥感多模态大模型
2025年1月,北京理工大学前沿交叉科学院数据流体团队研发出首个视觉提示遥感多模态大模型,相关成果以“EarthMarker: A Visual Prompting Multi-modal Large Language Model for Remote Sensing”为题,发表在国际顶级期刊《IEEE Transactions on Geoscience and Remote Sensing (TGRS)》。
EarthMarker为遥感通用大模型EarthGPT的延续,首次实现了遥感领域中基于视觉提示的多模态大模型,支持多粒度的视觉提示和自然语言联合提示,实现了多粒度解译遥感图像,并可灵活切换遥感图像解译粒度,如图像、区域和点粒度。此外,本文提出了首个遥感视觉提示大规模多模态数据集,包含约365万多模态{图像-点-文本}和{图像-区域-文本}配对数据,数据集已全部开源。
EarthMarker可完成复杂视觉推理任务,尤其在遥感目标关系分析任务中性能超越GPT-4V。如图1所示,EarthMarker展示出惊人的分析能力:其首先总结了视觉提示所标识区域分别为机场环境中的不同要素, 接着对相同类别的区域进行了聚类分析,并推理出这些标注区域在机场环境中的不同功能。

图1 EarthMarker完成复杂推理任务:遥感关键标关系分析(黄色高亮部分表示错误)
综合来讲,EarthMarker具备多才多艺的能力。如图2所示,EarthMarker可实现多粒度(如图像级、区域级和点级)遥感图像解译,擅长于各种视觉任务,包括场景分类、指定对象分类、图像描述、关系分析等。
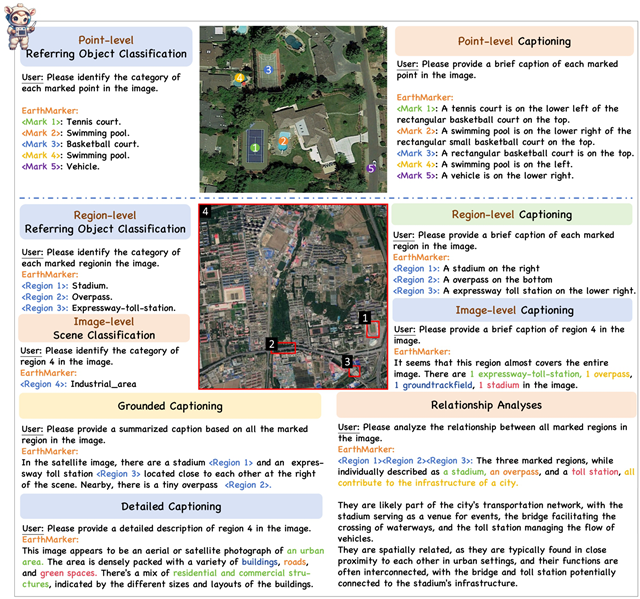
图2 EarthMarker具备多粒度遥感图像解译能力,可实现多任务推理
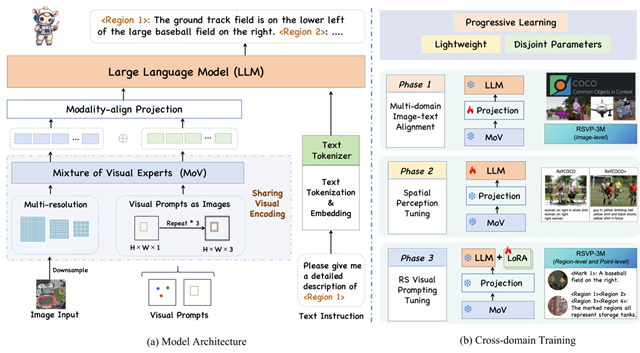
EarthMarker的总体架构如图3所示,提出了一种共享视觉编码机制,以增强视觉提示、整体图像和文本指令之间的交互理解。此外,文中设计了跨域三阶段学习策略,使得EarthMarker具备了空间感知和联合指令跟随能力。该研究贡献了视觉和语言联合提示多模态理解框架,并构建遥感多模态联合提示指令数据集,展示出了极大的应用潜力。
本文链接:https://19150.com/cul/21320.html